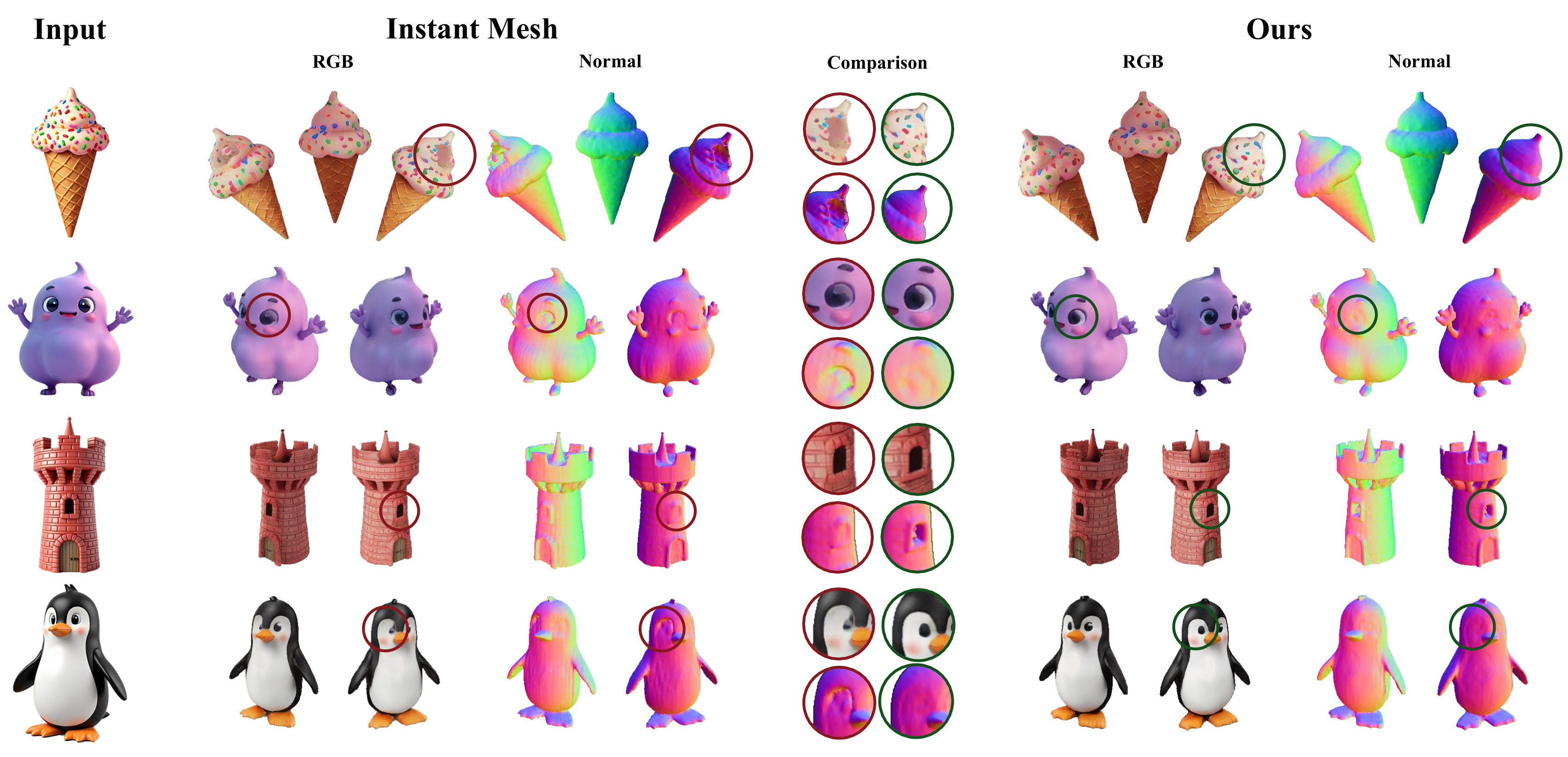
Our method emphasizes geometric consistency over appearance. By refining self-predicted depth and normals, it improves normal accuracy and corrects structural errors often hidden in RGB renderings of existing LRM-based methods.
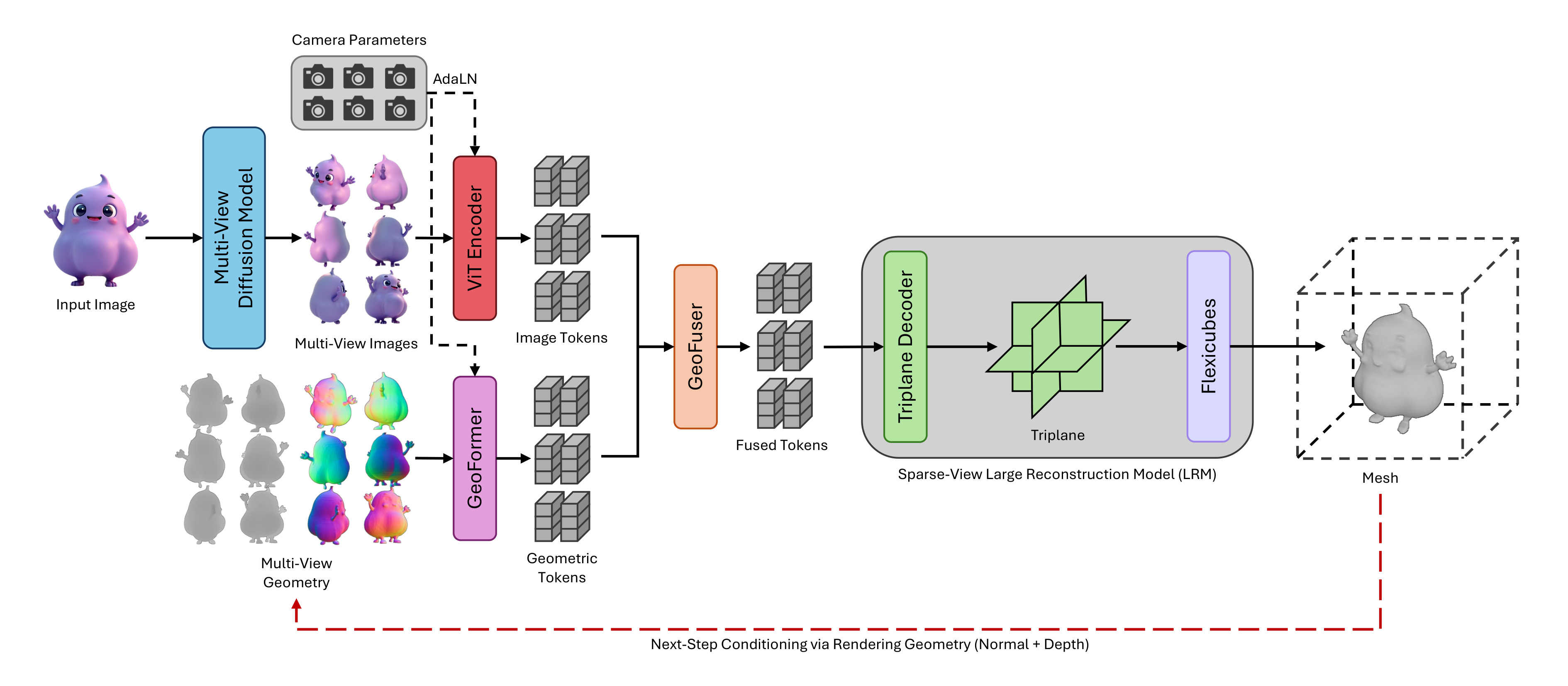
Single-image 3D reconstruction with large reconstruction models (LRMs) has advanced rapidly, yet reconstructions often exhibit geometric inconsistencies and misaligned details that limit fidelity. We introduce GeoFusionLRM, a geometry-aware self-correction framework that leverages the model's own normal and depth predictions to refine structural accuracy. Unlike prior approaches that rely solely on features extracted from the input image, GeoFusionLRM feeds back geometric cues through a dedicated transformer and fusion module, enabling the model to correct errors and enforce consistency with the conditioning image. This design improves the alignment between the reconstructed mesh and the input views without additional supervision or external signals. Extensive experiments demonstrate that GeoFusionLRM achieves sharper geometry, more consistent normals, and higher fidelity than state-of-the-art LRM baselines.
We present qualitative comparisons across multiple datasets, including GSO, OmniObject3D, and synthetic Flux-generated images, highlighting differences in geometric consistency, surface normals, and structural accuracy. Results are visualized using both RGB renderings and surface normal maps, allowing geometric artifacts that may be hidden in RGB appearance to be clearly revealed through normal-based inspection under changing viewpoints.







